Blog
TinyChat15M: A Small Conversational Language Model
The development of large language models (LLMs) like GPT-4 and Google’s Gemini marks a significant breakthrough in artificial intelligence. These models, with hundreds of billions of parameters such as GPT-3 with 175 billion and Google’s PaLM 2 with 540 billion, are capable of handling a wide range of tasks from creative writing to code generation. However, these advancements come at a considerable cost. For example, training GPT-3 required approximately 3640 petaflop per second days, amounting to millions of dollars in expenses and demanding over 700 GB of VRAM to run efficiently.
 Meta’s AI Research SuperCluster (Photo: Meta Platforms Inc.)
Meta’s AI Research SuperCluster (Photo: Meta Platforms Inc.)
The high resource demands and environmental impact of large models have spurred the development of smaller and more efficient language models, known as small language models (SLMs). These SLMs are designed to perform specific tasks while using only a fraction of the resources required by their larger counterparts. For instance, training GPT-3 consumed 1287 MWh of electricity, resulting in 502 metric tons of carbon emissions, which is equivalent to the annual emissions of 112 gasoline powered cars. In environments with limited computational resources, such as mobile devices and edge computing platforms, SLMs provide a practical and efficient alternative.
This blog introduces TinyChat15M, a fifteen million parameter conversational language model built on the Meta Llama 2 architecture. TinyChat15M is designed to operate on devices with as little as sixty MB of free memory and has been successfully run on a Sipeed LicheeRV Nano W, a mini sized RISC V development board with just 256 MB of DDR3 memory. Inspired by Dr. Andrej Karpathy’s llama2.c project, TinyChat15M demonstrates how small conversational language models can be both effective and resource efficient, making advanced AI capabilities more accessible and sustainable.
TinyChat: A Synthetic Dataset for Short Chat Conversations
TinyChat15M was trained on the TinyChat dataset, a synthetic collection of one million short chat conversations created using BASIC English, a backronym for British American Scientific International and Commercial English, designed for clear and simplified communication. The dataset was generated with a specialized version of GPT 4o, referred to as GPT 4o mini, which focuses on constructing dialogues primarily using BASIC English words and grammar. However, to maintain the coherence and fluidity of the conversations, some non BASIC English words were also included. The development of this dataset was inspired by the TinyStories dataset, which explores how small language models can produce coherent English text. Following methodologies outlined by Eldan et al. in their work titled TinyStories: How Small Can Language Models Be and Still Speak Coherent English, the TinyChat dataset carefully balances simplicity with linguistic coherence through the selective use of vocabulary and structure.
BASIC English is a simplified version of standard English designed by linguist and philosopher Charles Kay Ogden. It features a greatly reduced vocabulary and grammar, intended as an international auxiliary language and a tool for teaching English as a second language. Ogden introduced it in his 1930 book titled Basic English: A General Introduction with Rules and Grammar. The core of BASIC English consists of 850 words categorized into operations, things, picturable things, general qualities, and opposite qualities. These word roots are expanded using a defined set of affixes and forms to cover a broader range of expression.
To generate the TinyChat dataset, these 850 core words were divided into nouns, verbs, and adjectives, following a methodology similar to that used by Eldan et al. in their TinyStories paper. In their approach, they created a vocabulary of about 1500 basic words, mimicking the vocabulary of a typical three to four year old child, separated into nouns, verbs, and adjectives. For each story generation, three words, one verb, one noun, and one adjective, are randomly selected, prompting the model to create a story that combines these words, thereby increasing the diversity of the dataset.
Using this approach, the nouns, verbs, and adjectives from BASIC English were combined, resulting in over eight million possible word combinations. Due to the cost of generating the synthetic dataset, only one million of these combinations were randomly sampled and used as prompts for the GPT 4o mini model. The prompt template for this process is as follows.
System Prompt
You are a helpful, respectful, and honest assistant. Always aim to provide the most helpful and safe answers. Your responses should not contain any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Ensure that your answers are socially unbiased and positive. If a question does not make sense or is not factually coherent, explain why rather than providing an incorrect answer. If you do not know the answer, do not share false information. Use only BASIC English words, along with words that a typical three to four year old would understand. Follow these specific grammar rules: add es or ies to form plural nouns, ing or ed to turn verbs into adjectives, ing or er to turn verbs into nouns, ly to turn adjectives into adverbs, and er or est to compare amounts. Use un to create opposites of adjectives. Form questions by inverting the word order with do. Use normal English changes for verbs and pronouns, create compound words from two nouns or a noun and a direction, and write measures, numbers, money, days, months, years, and clock times in English words with no symbols or special characters, except for commas and periods. Do not use any punctuation marks except for commas and periods. Spell out all numbers as simple English words. Use industry specific or scientific terms as needed, such as plural, conjugation, noun, adjective, adverb, qualifier, operator, pronoun, and directive, which are necessary in language teaching but not part of BASIC English.
User Prompt
Generate a factually and logically coherent small talk conversation between a User and an Assistant, where they exchange six to ten sentences in total. Each sentence spoken by the User and the Assistant should be between ten and twenty words long. The conversation should be formatted as a single paragraph without line breaks or other textual formatting. It should begin with a
{starting}, convey a general feeling of{feeling}, and conclude with a{ending}ending. The conversation must include the noun{noun}, the verb{verb}, and the adjective{adjective}. Use the following text format:[INST]generate User’s sentence here[INST]generate Assistant’s sentence here.
In addition to the noun, verb, and adjective combinations, each prompt was carefully crafted to include a specific starting tone, convey a particular general feeling, and conclude with a defined ending. The starting tones are categorized as greetings, questions, or suggestions. The general feelings expressed include happiness, surprise, badness, fearfulness, anger, disgust, and sadness. The endings are designed to be either conclusive, reflective, or open. These combinations of starting tones, feelings, endings, verbs, nouns, and adjectives introduce both tonal and content diversity into the generated textual data. To ensure compatibility with Meta’s Llama 2 chat template, the conversations are encapsulated within the Llama 2 instruction tags [INST] and [INST]. The dataset is open source and hosted on Hugging Face.
Training the TinyChat15M Small Language Model
TinyChat15M was built upon Dr. Andrej Karpathy’s llama2.c project but was modified to suit the development and training of a conversational small language model. Although the main C file named run.c includes functionality for chatting with the language model, both the tokenization process and chat functionality required modifications to better accommodate a conversational model. In the TinyChat dataset, each conversation is already formatted with Llama 2 instruction tags, where the user’s dialogue is encapsulated within [INST] and [INST] tags and the model’s responses follow. However, to help the model distinguish between individual dialogues, Beginning of Sequence and End of Sequence tags are dynamically added during tokenization. These tags have token piece values <s> and </s>, with corresponding token IDs of 1 and 2.. Training the model in this manner enables it to predict and complete sentences on its own, making it a true conversational small language model that can be used with the llama2.c main C file.
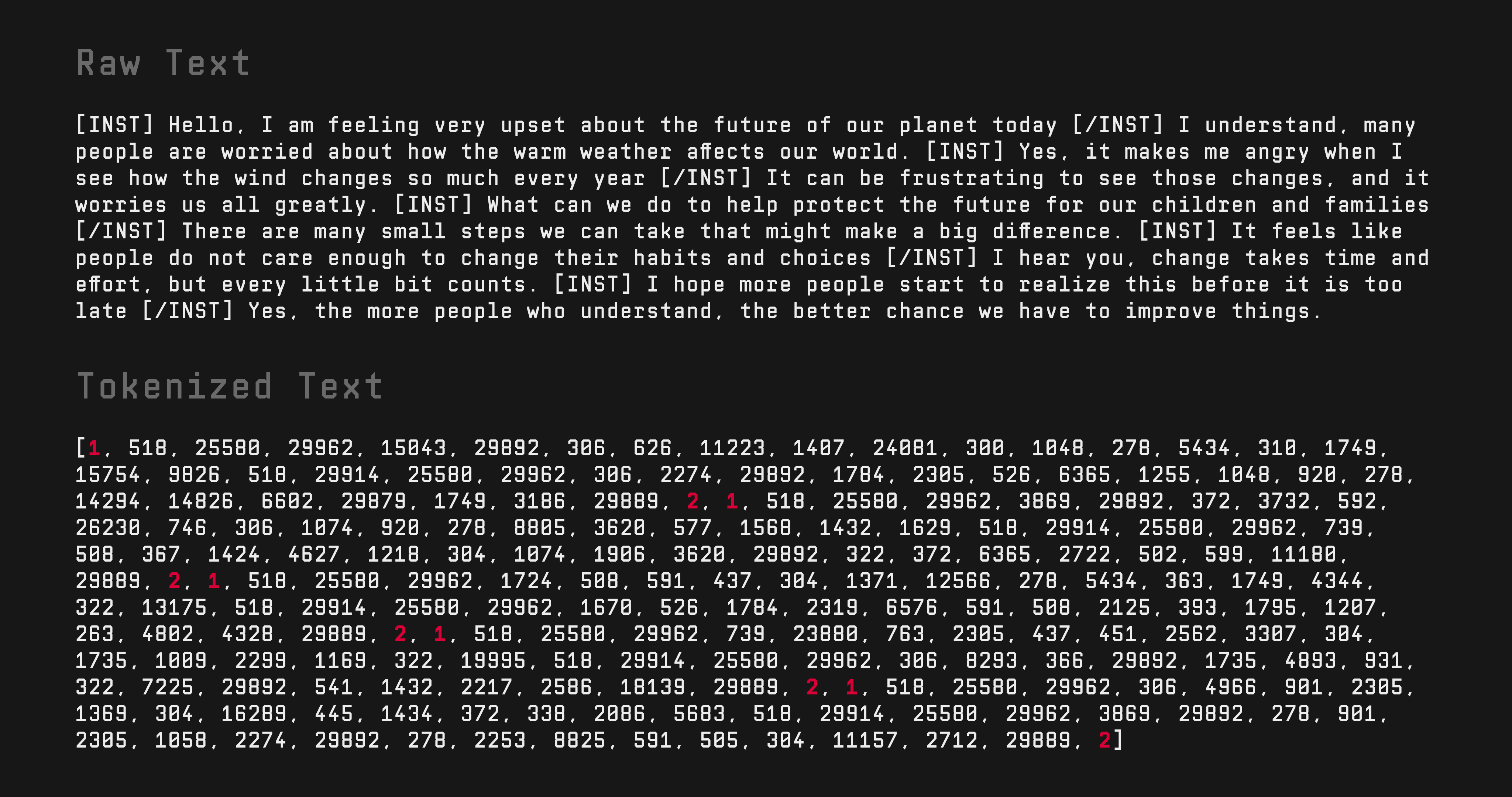 Raw text from the TinyChat dataset and the tokenized text with BOS and EOS tags highlighted in red
Raw text from the TinyChat dataset and the tokenized text with BOS and EOS tags highlighted in red
Additional changes were also necessary in the llama2.c main C file. Two key modifications include handling the BOS tags after the model generates a sentence and filtering out the instruction tags. Since the model learns to generate these tags in sequence, it might occasionally produce sentences that resemble those originally spoken by the user in the TinyChat dataset. This happens because the model cannot inherently distinguish between sentences spoken by the user and those generated by itself, as the instruction tags only separate one question, suggestion, or response from another. With these two modifications, TinyChat15M can be trained using the framework provided by the llama2.c project.
TinyChat15M was trained on Google Colab, a hosted Jupyter Notebook service from Google that provides free access to computing resources, including GPUs and TPUs, with no setup required. Although TinyChat15M is a small language model, it was trained on NVIDIA’s A100 Tensor Core GPU, available through Google Colab Pro. The training process ran for two hundred thousand iterations and took approximately five hours to complete. At the end of the training, I obtained both the original PyTorch .pt file and the llama2.c format .bin file. The .bin file is used for inference with the run.c file. The models are open source and available on Hugging Face.
Running TinyChat15M on the Sipeed LicheeRV Nano W
The Sipeed LicheeRV Nano W, equipped with 256 MB of DDR3 memory, serves as an ideal testbed for running TinyChat15M. Demonstrating TinyChat15M on this compact device highlights the model’s ability to deliver real time conversational AI despite limited memory resources. This setup is suited for scenarios where computational and memory efficiency are critical, yet functional AI capabilities remain essential. Despite its small size, the LicheeRV Nano W is capable of running Debian, an open source Linux distribution.
 The Sipeed LicheeRV Nano W next to an old stamp from Sri Lanka sourced from my dad’s stamp collection
The Sipeed LicheeRV Nano W next to an old stamp from Sri Lanka sourced from my dad’s stamp collection
The TinyChat15M model achieves an average generation speed of 9.40 tokens per second across five runs on the LicheeRV Nano. The video below demonstrates TinyChat15M in action on the LicheeRV Nano, where I, as the User, engage in a fictional conversation with an Assistant powered by the TinyChat15M model in a corporate setting. Despite having no prior context, the Assistant responds appropriately, mimicking a conversation one might have with a real colleague.
In the demo above, we can observe that when the Assistant is generating a reply, the CPU usage spikes to about 96 percent, while memory usage reaches approximately 27 percent of the available 228 MB, which equates to around 62 MB. Despite these compute and memory constraints, the TinyChat15M model is able to generate contextually coherent text at a reasonable speed.
I have fully open sourced this project, and the code for generating the synthetic TinyChat database, as well as the code for training and inferring the TinyChat15M model, can be found on my GitHub. If you have any suggestions or improvements, feel free to raise an issue or submit a pull request. With this project, I hope to inspire the AI community to focus on developing more general purpose conversational small language models. Advances in small language models would democratize access to AI, making it more affordable and accessible for everyone.